
Conforme dito previamente, agora vamos criar uma classe para fazer um micro benchmark para exemplificar o que foi explicado sobre SynchronizedMap e ConcurrentHashMap nos posts anteriores.
Quais foram os passos que segui?
1. Criei a classe TestBenchmark;
2. Passei uma implementação diferente como argumento para o método de teste Collections.synchronizedMap(new HashMap()) e ConcurrentHashMap();
3. Criei uma lógica para adicionar(PUT) e recuperar(GET) 600 mil entradas do Map;
4. Calculei a média de tempo em milissegundos para os processamentos;
5. Utilizei um ExecutorService simples para executar 5 threads em paralelo e para cada uma delas repetiremos por 5 vezes as iterações para capturar uma média de tempo.
6. Aproveitei e adicionei o Hashtable, que é a estrutura de dados base, ao teste.
Teste
package dev.ivanmarreta;
import java.util.Collections;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class TestBenchmark {
private static final int SIX_HUNDRED_THOUSAND = 600_000;
private static final int THREAD_POOL_SIZE = 5;
private static final int TIMES_TO_TEST = 5;
public static void main(String[] args) throws InterruptedException {
// Hashtable
microBenchmarkTest(new Hashtable<String, Integer>());
// Collections.synchronizedMap
microBenchmarkTest(Collections.synchronizedMap(new HashMap<String, Integer>()));
// ConcurrentHashMap
microBenchmarkTest(new ConcurrentHashMap<String, Integer>());
}
public static void microBenchmarkTest(final Map<String, Integer> map) throws InterruptedException {
System.out.println("Iniciando o teste de performance para: " + map.getClass());
long averageTime = 0;
for (int i = 0; i < TIMES_TO_TEST; i++) {
long startTime = System.nanoTime();
ExecutorService executor = Executors.newFixedThreadPool(THREAD_POOL_SIZE);
for (int j = 0; j < THREAD_POOL_SIZE; j++) {
executor.execute(() -> {
for (int key = 0; key < SIX_HUNDRED_THOUSAND; key++) {
Integer randomValue = (int) Math.ceil(Math.random() * SIX_HUNDRED_THOUSAND);
// GET
Integer value = map.get(String.valueOf(randomValue));
// PUT
map.put(String.valueOf(randomValue), randomValue);
}
});
}
executor.shutdown();
executor.awaitTermination(Integer.MAX_VALUE, TimeUnit.MINUTES);
long totalTime = (System.nanoTime() - startTime) / 1000000L;
averageTime += totalTime;
System.out.println("600 mil registros foram adicionados(PUT)/recuperados(GET) em " + totalTime + " ms");
}
System.out.println("Média de tempo de execução para a implementação " + map.getClass() + ": " + averageTime / TIMES_TO_TEST + " ms \n");
}
}
Nas linhas 56 e 57, chamo shutdown() para o executor service não esperar mais tasks e awaitTermination() para bloquear as threads até que as tasks finalizem.
Resultado do teste:
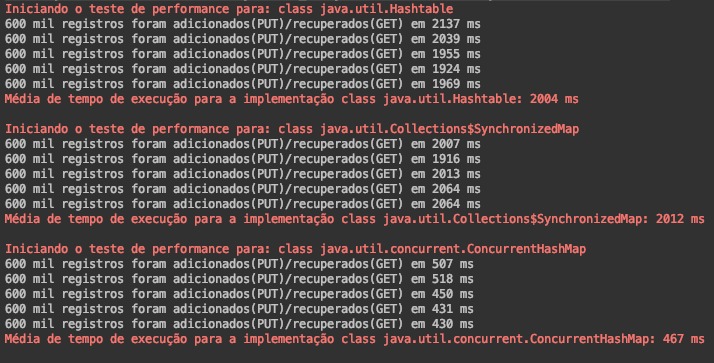
Máquina de teste: Macbook Pro 2.6GHz quad-core Intel Core i7 16GB
Conclusão:
Conforme conversamos sobre SynchronizedMap e ConcurrentHashMap, os resultados obtidos refletem a forma de acesso aos objetos simultaneamente.
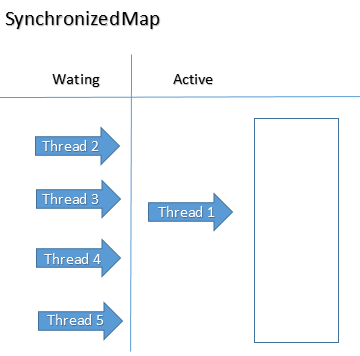
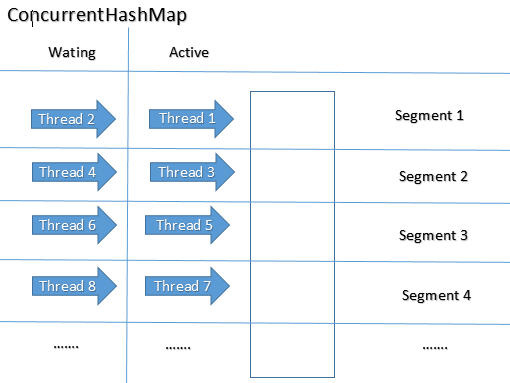
Portanto a estrátegia de lock do objeto ou de segmentos do objeto é bastante relevante, e parece-me ficar bem exemplificada.
Obrigado e até breve. 🙂

Leave a comment